When Is Big Data Big?
“Big data” is nothing new, but you may be seeking a proper definition of it. However, just as the word “big” is a relative term and a moving target, so is the definition of “big data.” The term is just as it sounds: a big amount of data. How do we define “big” in this case? Terabytes? Petabytes? Exabytes?
Big Data Defined
After researching this topic, I’ve settled on what I believe is the best definition. “Big data” is a dataset that a conventional transactional database cannot analyze due to its large size. So, there you go. That clears it up, right? Blog post complete?
But seriously, think about this for a minute. These online transactional processing databases (OLTPs) have been around for a long time. Computers have been collecting and storing data in these relational/schema systems for many, many years. Online analytical processing databases (OLAPs) could analyze this data well, especially with advances in hardware (like storage speed and computing power).
However, digital storage growth outpaces that of computing processing power by leaps and bounds. This allows us to collect more data, and at a faster rate than ever. In order for us to garner any meaning from it, though, we need to be able to process and analyze it at the same rate. Processing power falls short, and hence the big data era commences.
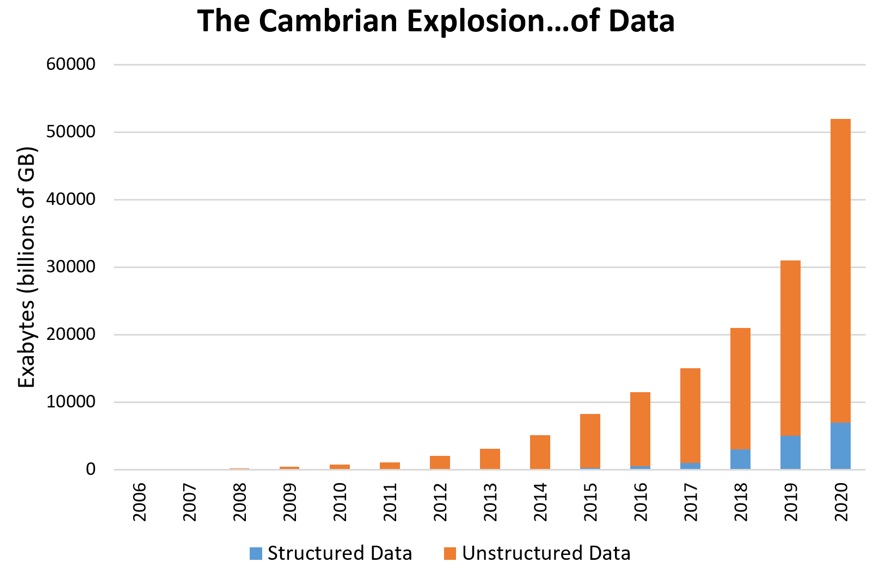
Source. Data originally from Patrick Cheesman’s LinkedIn article.
Data Explosion
The amount of data we collect and want to analyze calls for some different technical constructs to break the boundaries of traditional transaction-processing databases. Interestingly, the term “big data” doesn’t have to apply to only extremely large historical data stores. In fact, we could collect data at a lightning-fast rate resulting in an enormous dataset, analyze it, and get rid of the data. Another way to think about big data is to look at the “V” attributes that define big data. We started with the three Vs of big data, but experts have added to the list through the years. Now, we have the five Vs of big data:
- Volume—the amount of data being sampled/recorded
- Velocity—the speed at which the data is arriving, being generated, and analyzed
- Variety—the differences in how the data is structured
- Veracity—the trust you have in the data
- Value—the value derived from having the data
When Did Data Get Big?
Big data has been around since the inception of computing—and in fact even before that! In the past, developers would minimize the data collected in order to best utilize the available storage space. As the capacity to store data has increased, our need to optimize for small datasets has decreased. Cheaper hardware, easier storage, internet usage, and cloud computing have all contributed to the big data movement. Consider the below sources of data, and imagine how much data our systems are collecting:
- Website logs and clickstream data that analyze our customers’ online behavior
- Social media data, relationships, check-ins, reviews
- Cell towers, connections, and locations of connected devices
- Billions of devices—we have computers in our pockets!
- Supply chains, RFIDs, UPCs
- Blockchain ledgers and cryptocurrencies
- Image and video analysis
- Healthcare data
Every industry is investing in big data, and it’s in their interest to know all they can about their customer. This means more and more data collection points: those that we know of and voluntarily offer and those that we don’t. Even our cars are collecting data about us and our locations!
Crunching the Numbers
Now that we have all this data and it’s too big for our traditional OLTPs, how do we derive value from it? Let’s take a quick look at arguably the most popular algorithm in the processing of big data, MapReduce.
Consider a very large dataset. A single server analyzing and querying that data will potentially lead to many blocking operations. CPU capacity eventually limits the amount of data that a single server can process. What if we could take that enormous dataset, break it up into smaller pieces, spread (map) it across multiple nodes, and let those nodes process the smaller sets of data? They then have the results (reduced dataset) of the query we need and can report back. We call this distributed parallel processing, and the MapReduce algorithm follows this process. Google formalized MapReduce in 2004 when they published an article building on the concept of distributed parallel processing.
Apache Hadoop is an open-source software framework that came on the heels of Google releasing their MapReduce paper. Hadoop processes “big data” datasets utilizing the MapReduce methods across many nodes. It uses the Hadoop distributed file system (HDFS) to manage those nodes.
The Changing Stack
Since the advent of Hadoop and MapReduce, the big data technology stack is rapidly changing. Let’s briefly touch on some of the tools the big data community is using:
- Distributed file systems—Technologists and scientists are working to use cloud-based distributed files systems, which poses numerous challenges.
- Query abstraction layers—We started with Hive and Pig, which allowed us to abstract the Java query language using more familiar SQL query languages.
- Statistical programming and machine learning—The “R” computer programming language, Lucene, and Python are all players in this space.
In the past decade, the big data movement has spawned a somewhat new and ambiguous role: the data scientist. I would define a data scientist as a statistician who can build, analyze, and interpret sophisticated data models in context. The data scientist helps their employer analyze datasets and bring meaning to the specific industry.
Benefits of Big Data
There are many benefits to being able to capture huge amounts of data, analyze it, and use those results to solve problems:
- Trends in markets & new product development—Analyzing market or business conditions based on product usage data will help companies fine tune their products and see opportunities for new products. Data analysis is replacing much of the guesswork of sampling and surveying.
- Artificial intelligence—Machine learning requires large datasets, and instead of those insights coming from an analyst, the machine can gain valuable insights by looking into patterns of data. Think chatbots and virtual personal assistants!
- Fraud detection/prevention—By analyzing spending patterns and behaviors, machines can detect potential cases where theft or fraud is taking place.
- Predictive models around equipment—Collecting and analyzing logs generated by machines (manufacturing lines, servers, even smart cars) can trigger alerts to us about equipment that may be about to fail and needs to be replaced.
- Healthcare research/modeling—Combine DNA analysis with disease treatment analysis and you get customized healthcare solutions that are potentially more impactful in curing and prevention.
Cautions of Big Data
If you’re like me, maybe the section above talking about the benefits of big data gives you pause. Those benefits sound fantastic for the industries in which they reside, but what are we giving up? Certainly, there are some reasons to approach the big data world with caution:
- Data security—The more information we allow to be collected about us, the more trust we’re putting in the data collector to protect that data. When bad actors successfully attack Company ABC, they attack our data as well.
- Data Privacy—Along with data security is data privacy. Generally, we believe if we’re allowing companies to track data about our lives, they’re only using that data for the purposes they initially stated. We’re putting more trust in that tracker to not use the data for nefarious purposes, and that may backfire.
- Bad data/bad analytics—If we’re using big data analysis to drive decisions, what if some bad data corrupted the system? The logic used to determine outcomes will be compromised.
- Improper application—While big data can help us solve many problems, it certainly can’t be applied in every case. We have to be careful to recognize the improper application of big data. Big data experiments that are poorly designed can have meaningless or even damaging results.
An Exciting Future
Going forward, if we approach big data with caution as users and consumers, we can expect that its benefits will bring clarity and better quality to our lives. Big data already has an industry around it and gives us the opportunity to continue to innovate in that regard. As a person who’s always saying, “Let’s see what the data says,” I’m truly excited to see where big data will take us in the future.


